提起搜索,有句话人们常说:"外事不决问Google,内事不决问Baidu";不过这是我们对于Internet网站搜索的办法,对于很多的企业内网,如何解决?总不至于,拿着Google或Baidu咔咔的搜内网吧,呵呵~~~
嗯,没错,SharePoint是我们常提到的方案;我们先从SharePoint 2010基本配置开始,让我们在企业内网中把SharePoint的搜索先用起来。
- 启动Search Service Application
打开SharePoint管理中心依次到Manage service applications、Search Service Application,查看搜索服务应用是否已经开启,如图

- 加载PDF iFilter
SharePoint默认可以搜索Word, Power Point, Excel等文件,不过由于版权问题,默认情况下却不能搜索PDF文件
在我们开始搜索之前,让我们把这一部分加上吧
点击这个,下载Acrobat官方的安装程序,并在SharePoint服务器上安装,在还有一个帮助文档,不过它是配置2007的,供参考 ;点击这个,下载PDF的御用图片(17 x17的那个),放到SharePoint系统根目录的C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\14\TEMPLATE\IMAGES位置中 ;打开C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\14\TEMPLATE\XML位置的DOCICON.XML文件,在<ByExtension>节中添加一条记录 ,
<Mapping Key="pdf" Value="pdficon_small.gif" />
如图

回到管理中心的Manage service applications、点击Search Service Application、点击页面左边快速启动中的File Types,新建文件类型,如下

OK,到这里基本上搞定PDF文档设置,呼~~~
- 配置内容源
File Types的上面,点击Content Sources配置搜索用的内容源,注意以下几点
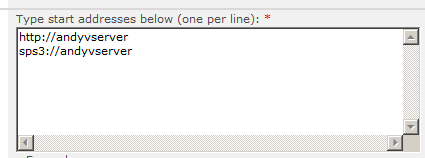
http开头的是搜索网站,可以加上其他站点及端口;sps3开头的是搜索人员,如果不用可以删掉
创建一个全量爬网计划和一个增量爬网计划,如图
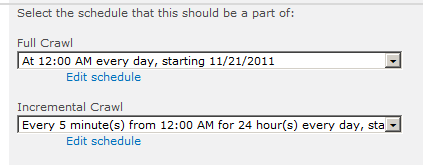
记得勾选上"Start full crawl of this content source",点击确定
若干分钟后,或喝杯茶后,爬网完毕,搜索在服务器端已经准备好,后续我们再来为客户端的搜索访问做准备
参考
Have a fun!
Andy